

How To Make A Data Set For Python
Watch Now This tutorial has a related video course created by the Real Python team. Spotter information technology together with the written tutorial to deepen your understanding: Explore Your Dataset With Pandas
Do you take a big dataset that's full of interesting insights, just you're not sure where to start exploring information technology? Has your boss asked you to generate some statistics from it, but they're not so easy to extract? These are precisely the use cases where Pandas and Python can help you! With these tools, y'all'll be able to slice a large dataset downwardly into manageable parts and glean insight from that information.
In this tutorial, you'll learn how to:
- Summate metrics nigh your data
- Perform basic queries and aggregations
- Discover and handle incorrect data, inconsistencies, and missing values
- Visualize your data with plots
You'll also acquire about the differences between the main data structures that Pandas and Python use. To follow along, you can get all of the case code in this tutorial at the link below:
Setting Up Your Environment
In that location are a few things you'll need to become started with this tutorial. Kickoff is a familiarity with Python'south built-in data structures, specially lists and dictionaries. For more information, check out Lists and Tuples in Python and Dictionaries in Python.
The 2d thing you'll need is a working Python environment. You can follow along in any terminal that has Python 3 installed. If you desire to see nicer output, specially for the large NBA dataset you'll exist working with, so you might want to run the examples in a Jupyter notebook.
The terminal affair you lot'll need is Pandas and other Python libraries, which yous can install with pip:
$ python3 -grand pip install requests pandas matplotlib You can besides use the Conda bundle manager:
$ conda install requests pandas matplotlib If yous're using the Anaconda distribution, so you're good to go! Anaconda already comes with the Pandas Python library installed.
The examples in this tutorial take been tested with Python iii.7 and Pandas 0.25.0, but they should as well piece of work in older versions. You tin get all the lawmaking examples you'll meet in this tutorial in a Jupyter notebook by clicking the link beneath:
Permit'south get started!
Using the Pandas Python Library
Now that you've installed Pandas, it's fourth dimension to accept a look at a dataset. In this tutorial, you'll clarify NBA results provided by FiveThirtyEight in a 17MB CSV file. Create a script download_nba_all_elo.py to download the information:
import requests download_url = "https://raw.githubusercontent.com/fivethirtyeight/information/master/nba-elo/nbaallelo.csv" target_csv_path = "nba_all_elo.csv" response = requests . get ( download_url ) response . raise_for_status () # Cheque that the request was successful with open ( target_csv_path , "wb" ) as f : f . write ( response . content ) impress ( "Download prepare." ) When you execute the script, it will salve the file nba_all_elo.csv in your current working directory.
At present y'all can utilize the Pandas Python library to take a look at your data:
>>>
>>> import pandas as pd >>> nba = pd . read_csv ( "nba_all_elo.csv" ) >>> blazon ( nba ) <grade 'pandas.core.frame.DataFrame'> Hither, you lot follow the convention of importing Pandas in Python with the pd allonym. Then, you utilise .read_csv() to read in your dataset and store it as a DataFrame object in the variable nba.
You can see how much data nba contains:
>>>
>>> len ( nba ) 126314 >>> nba . shape (126314, 23) You use the Python built-in office len() to determine the number of rows. You too utilise the .shape attribute of the DataFrame to see its dimensionality. The result is a tuple containing the number of rows and columns.
Now you know that there are 126,314 rows and 23 columns in your dataset. But how can you exist sure the dataset really contains basketball stats? You tin have a look at the kickoff v rows with .caput():
If you're following along with a Jupyter notebook, and so you'll see a issue like this:
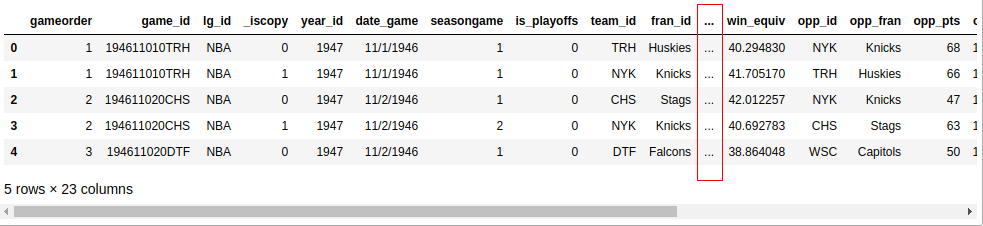
Unless your screen is quite large, your output probably won't display all 23 columns. Somewhere in the middle, you lot'll run into a cavalcade of ellipses (...) indicating the missing information. If you're working in a terminal, and then that'southward probably more readable than wrapping long rows. Nevertheless, Jupyter notebooks will allow you to scroll. You can configure Pandas to display all 23 columns similar this:
>>>
>>> pd . set_option ( "brandish.max.columns" , None ) While it's practical to see all the columns, yous probably won't demand vi decimal places! Change it to two:
>>>
>>> pd . set_option ( "brandish.precision" , 2 ) To verify that you've changed the options successfully, you lot can execute .head() over again, or you can brandish the last five rows with .tail() instead:
Now, you lot should see all the columns, and your data should evidence ii decimal places:

You tin can discover some further possibilities of .head() and .tail() with a small do. Can you impress the terminal iii lines of your DataFrame? Expand the code cake below to see the solution:
Here's how to print the last three lines of nba:
Your output should look something similar this:
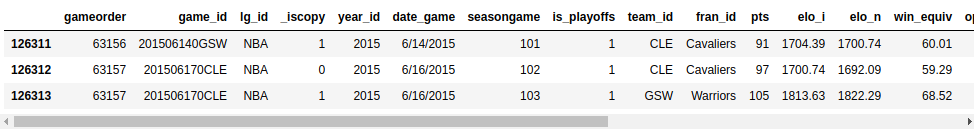
You can come across the last 3 lines of your dataset with the options you've set in a higher place.
Similar to the Python standard library, functions in Pandas also come with several optional parameters. Whenever you crash-land into an example that looks relevant but is slightly dissimilar from your employ instance, check out the official documentation. The chances are adept that yous'll discover a solution by tweaking some optional parameters!
Getting to Know Your Data
Y'all've imported a CSV file with the Pandas Python library and had a first expect at the contents of your dataset. Then far, you've only seen the size of your dataset and its outset and last few rows. Next, y'all'll learn how to examine your data more systematically.
Displaying Data Types
The first step in getting to know your data is to detect the different data types it contains. While you lot tin can put anything into a list, the columns of a DataFrame contain values of a specific information type. When you compare Pandas and Python data structures, you'll encounter that this beliefs makes Pandas much faster!
You tin can display all columns and their data types with .info():
This volition produce the post-obit output:
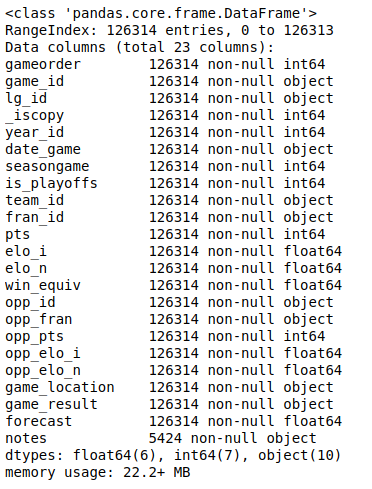
Y'all'll run into a listing of all the columns in your dataset and the type of data each column contains. Here, you tin can see the data types int64, float64, and object. Pandas uses the NumPy library to work with these types. Afterwards, you'll meet the more complex categorical information blazon, which the Pandas Python library implements itself.
The object data type is a special 1. According to the Pandas Cookbook, the object information type is "a catch-all for columns that Pandas doesn't recognize every bit whatsoever other specific type." In practice, it often means that all of the values in the column are strings.
Although you can store capricious Python objects in the object information blazon, you should exist aware of the drawbacks to doing and so. Strange values in an object column can harm Pandas' functioning and its interoperability with other libraries. For more information, bank check out the official getting started guide.
Showing Nuts Statistics
Now that y'all've seen what data types are in your dataset, it'south time to get an overview of the values each column contains. You tin can do this with .describe():
This function shows you some basic descriptive statistics for all numeric columns:
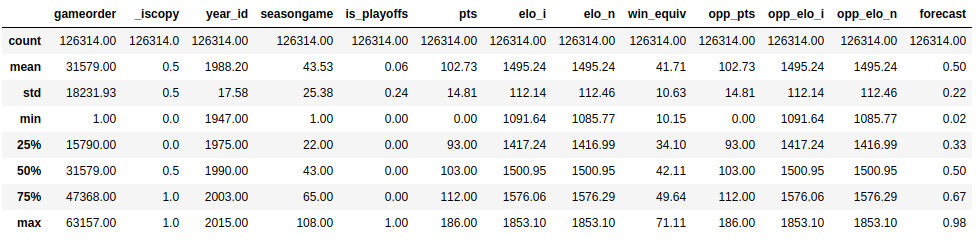
.depict() only analyzes numeric columns by default, just you can provide other data types if you use the include parameter:
>>>
>>> import numpy as np >>> nba . depict ( include = object ) .describe() won't try to calculate a mean or a standard deviation for the object columns, since they mostly include text strings. However, it will all the same display some descriptive statistics:

Take a await at the team_id and fran_id columns. Your dataset contains 104 different team IDs, but only 53 different franchise IDs. Furthermore, the virtually frequent team ID is BOS, just the most frequent franchise ID Lakers. How is that possible? You'll need to explore your dataset a chip more than to reply this question.
Exploring Your Dataset
Exploratory data analysis can assist you lot answer questions about your dataset. For example, yous can examine how often specific values occur in a column:
>>>
>>> nba [ "team_id" ] . value_counts () BOS 5997 NYK 5769 LAL 5078 ... SDS 11 >>> nba [ "fran_id" ] . value_counts () Proper name: team_id, Length: 104, dtype: int64 Lakers 6024 Celtics 5997 Knicks 5769 ... Huskies lx Name: fran_id, dtype: int64 It seems that a team named "Lakers" played 6024 games, but just 5078 of those were played by the Los Angeles Lakers. Detect out who the other "Lakers" team is:
>>>
>>> nba . loc [ nba [ "fran_id" ] == "Lakers" , "team_id" ] . value_counts () LAL 5078 MNL 946 Name: team_id, dtype: int64 Indeed, the Minneapolis Lakers ("MNL") played 946 games. Y'all tin can even find out when they played those games. For that, you'll first define a column that converts the value of date_game to the datetime data blazon. Then you lot tin can use the min and max aggregate functions, to find the starting time and final games of Minneapolis Lakers:
>>>
>>> nba [ "date_played" ] = pd . to_datetime ( nba [ "date_game" ]) >>> nba . loc [ nba [ "team_id" ] == "MNL" , "date_played" ] . min () Timestamp('1948-xi-04 00:00:00') >>> nba . loc [ nba [ 'team_id' ] == 'MNL' , 'date_played' ] . max () Timestamp('1960-03-26 00:00:00') >>> nba . loc [ nba [ "team_id" ] == "MNL" , "date_played" ] . agg (( "min" , "max" )) min 1948-11-04 max 1960-03-26 Name: date_played, dtype: datetime64[ns] It looks similar the Minneapolis Lakers played between the years of 1948 and 1960. That explains why you might not recognize this team!
Yous've likewise found out why the Boston Celtics team "BOS" played the nearly games in the dataset. Let's clarify their history also a niggling bit. Find out how many points the Boston Celtics accept scored during all matches contained in this dataset. Expand the lawmaking cake below for the solution:
Similar to the .min() and .max() aggregate functions, you can also use .sum():
>>>
>>> nba . loc [ nba [ "team_id" ] == "BOS" , "pts" ] . sum () 626484 The Boston Celtics scored a total of 626,484 points.
You've got a taste for the capabilities of a Pandas DataFrame. In the following sections, you'll expand on the techniques you've just used, but first, you lot'll zoom in and learn how this powerful data structure works.
Getting to Know Pandas' Data Structures
While a DataFrame provides functions that can experience quite intuitive, the underlying concepts are a fleck trickier to understand. For this reason, you lot'll set aside the vast NBA DataFrame and build some smaller Pandas objects from scratch.
Agreement Series Objects
Python's most basic data structure is the listing, which is besides a adept starting point for getting to know pandas.Series objects. Create a new Serial object based on a list:
>>>
>>> revenues = pd . Series ([ 5555 , 7000 , 1980 ]) >>> revenues 0 5555 ane 7000 2 1980 dtype: int64 Yous've used the list [5555, 7000, 1980] to create a Series object called revenues. A Series object wraps ii components:
- A sequence of values
- A sequence of identifiers, which is the index
Y'all tin access these components with .values and .index, respectively:
>>>
>>> revenues . values array([5555, 7000, 1980]) >>> revenues . index RangeIndex(start=0, stop=3, step=one) revenues.values returns the values in the Series, whereas revenues.alphabetize returns the positional index.
While Pandas builds on NumPy, a significant difference is in their indexing. Just like a NumPy array, a Pandas Series also has an integer index that's implicitly defined. This implicit alphabetize indicates the element's position in the Series.
Notwithstanding, a Serial can also have an arbitrary type of index. You tin retrieve of this explicit index as labels for a specific row:
>>>
>>> city_revenues = pd . Series ( ... [ 4200 , 8000 , 6500 ], ... index = [ "Amsterdam" , "Toronto" , "Tokyo" ] ... ) >>> city_revenues Amsterdam 4200 Toronto 8000 Tokyo 6500 dtype: int64 Hither, the alphabetize is a list of city names represented by strings. You may have noticed that Python dictionaries use string indices equally well, and this is a handy illustration to continue in mind! You tin can utilise the code blocks to a higher place to distinguish between 2 types of Series:
-
revenues: ThisSeriesbehaves like a Python list because it merely has a positional alphabetize. -
city_revenues: ThisSerialacts like a Python dictionary because it features both a positional and a label alphabetize.
Hither'south how to construct a Series with a characterization alphabetize from a Python dictionary:
>>>
>>> city_employee_count = pd . Serial ({ "Amsterdam" : 5 , "Tokyo" : 8 }) >>> city_employee_count Amsterdam 5 Tokyo 8 dtype: int64 The dictionary keys become the index, and the lexicon values are the Series values.
Just similar dictionaries, Series also back up .keys() and the in keyword:
>>>
>>> city_employee_count . keys () Index(['Amsterdam', 'Tokyo'], dtype='object') >>> "Tokyo" in city_employee_count True >>> "New York" in city_employee_count False You can use these methods to answer questions about your dataset quickly.
Understanding DataFrame Objects
While a Serial is a pretty powerful data structure, information technology has its limitations. For example, y'all can only shop i attribute per key. Equally you've seen with the nba dataset, which features 23 columns, the Pandas Python library has more to offer with its DataFrame . This data construction is a sequence of Series objects that share the same index.
If you lot've followed along with the Series examples, and so you should already have two Series objects with cities equally keys:
-
city_revenues -
city_employee_count
You tin can combine these objects into a DataFrame by providing a dictionary in the constructor. The dictionary keys will become the cavalcade names, and the values should incorporate the Serial objects:
>>>
>>> city_data = pd . DataFrame ({ ... "revenue" : city_revenues , ... "employee_count" : city_employee_count ... }) >>> city_data revenue employee_count Amsterdam 4200 5.0 Tokyo 6500 viii.0 Toronto 8000 NaN Note how Pandas replaced the missing employee_count value for Toronto with NaN.
The new DataFrame index is the wedlock of the two Series indices:
>>>
>>> city_data . index Alphabetize(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object') But like a Series, a DataFrame also stores its values in a NumPy assortment:
>>>
>>> city_data . values array([[iv.2e+03, v.0e+00], [6.5e+03, 8.0e+00], [8.0e+03, nan]]) You tin besides refer to the two dimensions of a DataFrame equally axes:
>>>
>>> city_data . axes [Alphabetize(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object'), Index(['revenue', 'employee_count'], dtype='object')] >>> city_data . axes [ 0 ] Index(['Amsterdam', 'Tokyo', 'Toronto'], dtype='object') >>> city_data . axes [ 1 ] Index(['revenue', 'employee_count'], dtype='object') The centrality marked with 0 is the row alphabetize, and the axis marked with ane is the cavalcade index. This terminology is of import to know because yous'll encounter several DataFrame methods that accept an axis parameter.
A DataFrame is also a dictionary-similar data structure, so information technology also supports .keys() and the in keyword. Nonetheless, for a DataFrame these don't chronicle to the alphabetize, only to the columns:
>>>
>>> city_data . keys () Index(['revenue', 'employee_count'], dtype='object') >>> "Amsterdam" in city_data False >>> "revenue" in city_data True You tin can see these concepts in action with the bigger NBA dataset. Does information technology contain a cavalcade called "points", or was information technology chosen "pts"? To reply this question, brandish the index and the axes of the nba dataset, then expand the code cake beneath for the solution:
Because y'all didn't specify an index column when you read in the CSV file, Pandas has assigned a RangeIndex to the DataFrame:
>>>
>>> nba . index RangeIndex(start=0, stop=126314, footstep=1) nba, similar all DataFrame objects, has two axes:
>>>
>>> nba . axes [RangeIndex(starting time=0, stop=126314, step=ane), Index(['gameorder', 'game_id', 'lg_id', '_iscopy', 'year_id', 'date_game', 'seasongame', 'is_playoffs', 'team_id', 'fran_id', 'pts', 'elo_i', 'elo_n', 'win_equiv', 'opp_id', 'opp_fran', 'opp_pts', 'opp_elo_i', 'opp_elo_n', 'game_location', 'game_result', 'forecast', 'notes'], dtype='object')] Y'all tin bank check the existence of a column with .keys():
>>>
>>> "points" in nba . keys () Fake >>> "pts" in nba . keys () True The column is chosen "pts", not "points".
As yous utilise these methods to answer questions about your dataset, be sure to continue in heed whether you lot're working with a Serial or a DataFrame so that your estimation is accurate.
Accessing Serial Elements
In the section above, you've created a Pandas Series based on a Python list and compared the ii data structures. You've seen how a Series object is similar to lists and dictionaries in several ways. A further similarity is that you tin use the indexing operator ([]) for Series as well.
Y'all'll also learn how to apply two Pandas-specific access methods:
-
.loc -
.iloc
You'll see that these information admission methods can be much more readable than the indexing operator.
Using the Indexing Operator
Recall that a Series has two indices:
- A positional or implicit index, which is always a
RangeIndex - A label or explicit index, which tin can contain any hashable objects
Side by side, revisit the city_revenues object:
>>>
>>> city_revenues Amsterdam 4200 Toronto 8000 Tokyo 6500 dtype: int64 You tin can conveniently access the values in a Serial with both the label and positional indices:
>>>
>>> city_revenues [ "Toronto" ] 8000 >>> city_revenues [ 1 ] 8000 Yous can also use negative indices and slices, merely similar yous would for a list:
>>>
>>> city_revenues [ - 1 ] 6500 >>> city_revenues [ 1 :] Toronto 8000 Tokyo 6500 dtype: int64 >>> city_revenues [ "Toronto" :] Toronto 8000 Tokyo 6500 dtype: int64 If y'all desire to learn more virtually the possibilities of the indexing operator, and then bank check out Lists and Tuples in Python.
Using .loc and .iloc
The indexing operator ([]) is convenient, merely there's a caveat. What if the labels are also numbers? Say y'all have to work with a Serial object like this:
>>>
>>> colors = pd . Series ( ... [ "red" , "royal" , "bluish" , "green" , "yellow" ], ... index = [ i , two , iii , 5 , eight ] ... ) >>> colors i red 2 regal three blue 5 green eight yellowish dtype: object What will colors[1] render? For a positional alphabetize, colors[1] is "purple". Still, if you go by the characterization alphabetize, then colors[i] is referring to "blood-red".
The skilful news is, you don't have to effigy it out! Instead, to avert confusion, the Pandas Python library provides two data admission methods:
-
.locrefers to the characterization index. -
.ilocrefers to the positional index.
These data access methods are much more readable:
>>>
>>> colors . loc [ 1 ] 'red' >>> colors . iloc [ one ] 'purple' colors.loc[1] returned "reddish", the element with the label 1. colors.iloc[1] returned "purple", the element with the index 1.
The post-obit figure shows which elements .loc and .iloc refer to:
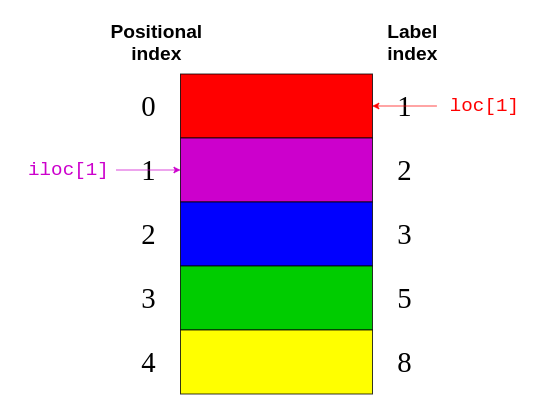
Over again, .loc points to the characterization index on the correct-hand side of the epitome. Meanwhile, .iloc points to the positional index on the left-hand side of the motion picture.
It's easier to keep in mind the distinction betwixt .loc and .iloc than it is to effigy out what the indexing operator will return. Even if you're familiar with all the quirks of the indexing operator, it can be dangerous to assume that everybody who reads your code has internalized those rules as well!
.loc and .iloc also support the features you would expect from indexing operators, similar slicing. However, these data access methods have an important difference. While .iloc excludes the closing element, .loc includes it. Take a look at this code block:
>>>
>>> # Return the elements with the implicit index: 1, two >>> colors . iloc [ 1 : three ] 2 purple 3 blueish dtype: object If you compare this lawmaking with the image above, then you can encounter that colors.iloc[ane:3] returns the elements with the positional indices of 1 and 2. The closing item "green" with a positional index of three is excluded.
On the other hand, .loc includes the closing chemical element:
>>>
>>> # Return the elements with the explicit index betwixt 3 and 8 >>> colors . loc [ 3 : eight ] iii blue 5 green eight xanthous dtype: object This code block says to render all elements with a label index between iii and 8. Here, the closing item "yellow" has a label alphabetize of 8 and is included in the output.
You tin too pass a negative positional index to .iloc:
>>>
>>> colors . iloc [ - 2 ] 'light-green' You lot offset from the finish of the Series and return the second element.
You lot can use the code blocks higher up to distinguish between two Series behaviors:
- Y'all tin use
.ilocon aSeriessimilar to using[]on a list. - You lot can utilise
.locon aSerieslike to using[]on a lexicon.
Exist sure to proceed these distinctions in heed as you lot admission elements of your Series objects.
Accessing DataFrame Elements
Since a DataFrame consists of Serial objects, yous can utilize the very aforementioned tools to access its elements. The crucial difference is the boosted dimension of the DataFrame. Y'all'll utilise the indexing operator for the columns and the access methods .loc and .iloc on the rows.
Using the Indexing Operator
If you think of a DataFrame as a dictionary whose values are Series, and then information technology makes sense that y'all tin admission its columns with the indexing operator:
>>>
>>> city_data [ "revenue" ] Amsterdam 4200 Tokyo 6500 Toronto 8000 Name: revenue, dtype: int64 >>> type ( city_data [ "revenue" ]) pandas.core.series.Series Here, y'all utilise the indexing operator to select the column labeled "revenue".
If the column name is a string, and then y'all can apply attribute-style accessing with dot notation besides:
>>>
>>> city_data . revenue Amsterdam 4200 Tokyo 6500 Toronto 8000 Name: revenue, dtype: int64 city_data["revenue"] and city_data.revenue return the same output.
There'southward 1 situation where accessing DataFrame elements with dot notation may not piece of work or may lead to surprises. This is when a column name coincides with a DataFrame attribute or method name:
>>>
>>> toys = pd . DataFrame ([ ... { "proper name" : "brawl" , "shape" : "sphere" }, ... { "name" : "Rubik's cube" , "shape" : "cube" } ... ]) >>> toys [ "shape" ] 0 sphere 1 cube Name: shape, dtype: object >>> toys . shape (2, two) The indexing operation toys["shape"] returns the correct information, only the aspect-manner operation toys.shape still returns the shape of the DataFrame. Yous should only use attribute-style accessing in interactive sessions or for read operations. You shouldn't use it for production code or for manipulating data (such every bit defining new columns).
Using .loc and .iloc
Similar to Series, a DataFrame also provides .loc and .iloc data access methods. Remember, .loc uses the label and .iloc the positional index:
>>>
>>> city_data . loc [ "Amsterdam" ] revenue 4200.0 employee_count 5.0 Name: Amsterdam, dtype: float64 >>> city_data . loc [ "Tokyo" : "Toronto" ] acquirement employee_count Tokyo 6500 8.0 Toronto 8000 NaN >>> city_data . iloc [ 1 ] revenue 6500.0 employee_count 8.0 Name: Tokyo, dtype: float64 Each line of code selects a different row from city_data:
-
city_data.loc["Amsterdam"]selects the row with the label index"Amsterdam". -
city_data.loc["Tokyo": "Toronto"]selects the rows with characterization indices from"Tokyo"to"Toronto". Remember,.locis inclusive. -
city_data.iloc[1]selects the row with the positional alphabetize1, which is"Tokyo".
Alright, you've used .loc and .iloc on small data structures. Now, it's time to practice with something bigger! Use a data access method to display the second-to-last row of the nba dataset. And so, expand the code block beneath to see a solution:
The second-to-last row is the row with the positional alphabetize of -2. Y'all can brandish it with .iloc:
>>>
>>> nba . iloc [ - 2 ] gameorder 63157 game_id 201506170CLE lg_id NBA _iscopy 0 year_id 2015 date_game half-dozen/sixteen/2015 seasongame 102 is_playoffs 1 team_id CLE fran_id Cavaliers pts 97 elo_i 1700.74 elo_n 1692.09 win_equiv 59.29 opp_id GSW opp_fran Warriors opp_pts 105 opp_elo_i 1813.63 opp_elo_n 1822.29 game_location H game_result L forecast 0.48 notes NaN date_played 2015-06-16 00:00:00 Name: 126312, dtype: object You'll meet the output equally a Series object.
For a DataFrame, the data access methods .loc and .iloc also take a 2nd parameter. While the first parameter selects rows based on the indices, the second parameter selects the columns. You can utilise these parameters together to select a subset of rows and columns from your DataFrame:
>>>
>>> city_data . loc [ "Amsterdam" : "Tokyo" , "revenue" ] Amsterdam 4200 Tokyo 6500 Name: revenue, dtype: int64 Note that you divide the parameters with a comma (,). The showtime parameter, "Amsterdam" : "Tokyo," says to select all rows betwixt those two labels. The 2nd parameter comes after the comma and says to select the "acquirement" column.
It'due south time to encounter the same construct in action with the bigger nba dataset. Select all games betwixt the labels 5555 and 5559. You're simply interested in the names of the teams and the scores, so select those elements as well. Expand the code block below to see a solution:
Beginning, define which rows you want to see, then list the relevant columns:
>>>
>>> nba . loc [ 5555 : 5559 , [ "fran_id" , "opp_fran" , "pts" , "opp_pts" ]] You apply .loc for the characterization alphabetize and a comma (,) to separate your two parameters.
You should encounter a modest part of your quite huge dataset:
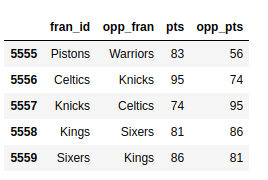
The output is much easier to read!
With data access methods like .loc and .iloc, you tin can select just the right subset of your DataFrame to help you respond questions about your dataset.
Querying Your Dataset
You've seen how to access subsets of a huge dataset based on its indices. Now, you'll select rows based on the values in your dataset'south columns to query your data. For case, y'all can create a new DataFrame that contains only games played after 2010:
>>>
>>> current_decade = nba [ nba [ "year_id" ] > 2010 ] >>> current_decade . shape (12658, 24) You lot now have 24 columns, but your new DataFrame only consists of rows where the value in the "year_id" column is greater than 2010.
You can also select the rows where a specific field is not goose egg:
>>>
>>> games_with_notes = nba [ nba [ "notes" ] . notnull ()] >>> games_with_notes . shape (5424, 24) This can exist helpful if you want to avoid any missing values in a column. Yous can as well apply .notna() to achieve the same goal.
Yous tin fifty-fifty access values of the object data type as str and perform string methods on them:
>>>
>>> ers = nba [ nba [ "fran_id" ] . str . endswith ( "ers" )] >>> ers . shape (27797, 24) You use .str.endswith() to filter your dataset and detect all games where the habitation squad's name ends with "ers".
You lot can combine multiple criteria and query your dataset besides. To do this, exist sure to put each one in parentheses and utilize the logical operators | and & to separate them.
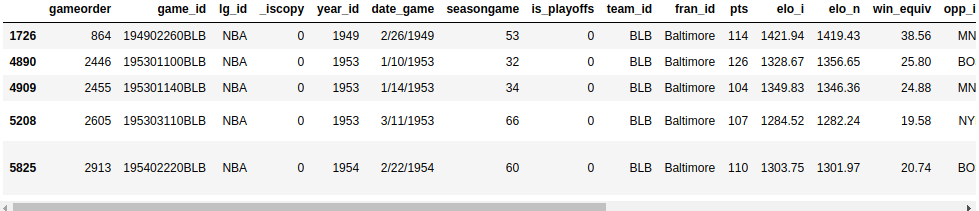
Do a search for Baltimore games where both teams scored over 100 points. In guild to see each game only once, y'all'll need to exclude duplicates:
>>>
>>> nba [ ... ( nba [ "_iscopy" ] == 0 ) & ... ( nba [ "pts" ] > 100 ) & ... ( nba [ "opp_pts" ] > 100 ) & ... ( nba [ "team_id" ] == "BLB" ) ... ] Here, you use nba["_iscopy"] == 0 to include only the entries that aren't copies.
Your output should contain five eventful games:
Attempt to build another query with multiple criteria. In the spring of 1992, both teams from Los Angeles had to play a home game at another court. Query your dataset to find those two games. Both teams have an ID starting with "LA". Aggrandize the code block below to see a solution:
You can employ .str to find the team IDs that start with "LA", and you can presume that such an unusual game would have some notes:
>>>
>>> nba [ ... ( nba [ "_iscopy" ] == 0 ) & ... ( nba [ "team_id" ] . str . startswith ( "LA" )) & ... ( nba [ "year_id" ] == 1992 ) & ... ( nba [ "notes" ] . notnull ()) ... ] Your output should show two games on the day 5/3/1992:
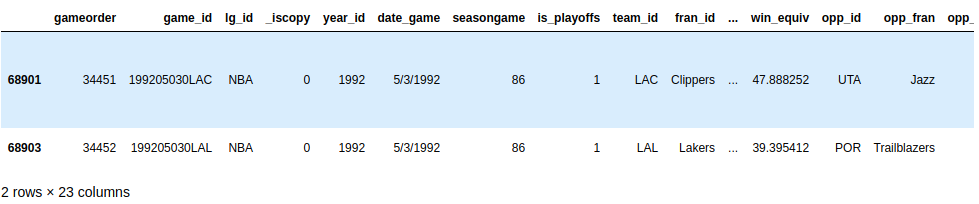
Dainty find!
When y'all know how to query your dataset with multiple criteria, you'll exist able to answer more than specific questions about your dataset.
Grouping and Aggregating Your Data
You lot may also want to learn other features of your dataset, like the sum, mean, or average value of a grouping of elements. Luckily, the Pandas Python library offers grouping and aggregation functions to help you lot reach this chore.
A Serial has more xx dissimilar methods for calculating descriptive statistics. Here are some examples:
>>>
>>> city_revenues . sum () 18700 >>> city_revenues . max () 8000 The first method returns the total of city_revenues, while the 2d returns the max value. At that place are other methods you can utilise, like .min() and .mean().
Recall, a column of a DataFrame is actually a Series object. For this reason, you tin use these same functions on the columns of nba:
>>>
>>> points = nba [ "pts" ] >>> type ( points ) <class 'pandas.cadre.series.Serial'> >>> points . sum () 12976235 A DataFrame can have multiple columns, which introduces new possibilities for aggregations, similar grouping:
>>>
>>> nba . groupby ( "fran_id" , sort = Faux )[ "pts" ] . sum () fran_id Huskies 3995 Knicks 582497 Stags 20398 Falcons 3797 Capitols 22387 ... By default, Pandas sorts the grouping keys during the call to .groupby(). If you don't want to sort, then pass sort=False. This parameter can lead to performance gains.
Y'all tin too group by multiple columns:
>>>
>>> nba [ ... ( nba [ "fran_id" ] == "Spurs" ) & ... ( nba [ "year_id" ] > 2010 ) ... ] . groupby ([ "year_id" , "game_result" ])[ "game_id" ] . count () year_id game_result 2011 L 25 W 63 2012 L 20 W threescore 2013 Fifty xxx W 73 2014 Fifty 27 Due west 78 2015 Fifty 31 W 58 Proper noun: game_id, dtype: int64 You tin do these nuts with an exercise. Take a expect at the Gold State Warriors' 2014-xv season (year_id: 2015). How many wins and losses did they score during the regular season and the playoffs? Aggrandize the code cake below for the solution:
First, you can grouping by the "is_playoffs" field, and then by the consequence:
>>>
>>> nba [ ... ( nba [ "fran_id" ] == "Warriors" ) & ... ( nba [ "year_id" ] == 2015 ) ... ] . groupby ([ "is_playoffs" , "game_result" ])[ "game_id" ] . count () is_playoffs game_result 0 L 15 W 67 ane L 5 W 16 is_playoffs=0 shows the results for the regular flavour, and is_playoffs=1 shows the results for the playoffs.
In the examples above, yous've just scratched the surface of the aggregation functions that are bachelor to you in the Pandas Python library. To run across more than examples of how to apply them, cheque out Pandas GroupBy: Your Guide to Grouping Data in Python.
Manipulating Columns
Yous'll demand to know how to manipulate your dataset's columns in different phases of the data analysis procedure. You can add together and drop columns as role of the initial data cleaning phase, or subsequently based on the insights of your analysis.
Create a copy of your original DataFrame to work with:
>>>
>>> df = nba . copy () >>> df . shape (126314, 24) Y'all tin can ascertain new columns based on the existing ones:
>>>
>>> df [ "difference" ] = df . pts - df . opp_pts >>> df . shape (126314, 25) Hither, you used the "pts" and "opp_pts" columns to create a new one chosen "difference". This new column has the same functions as the onetime ones:
>>>
>>> df [ "difference" ] . max () 68 Hither, you used an aggregation office .max() to find the largest value of your new column.
You can likewise rename the columns of your dataset. It seems that "game_result" and "game_location" are too verbose, so go ahead and rename them now:
>>>
>>> renamed_df = df . rename ( ... columns = { "game_result" : "consequence" , "game_location" : "location" } ... ) >>> renamed_df . info () <form 'pandas.core.frame.DataFrame'> RangeIndex: 126314 entries, 0 to 126313 Data columns (total 25 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 gameorder 126314 not-zip int64 ... nineteen location 126314 non-nada object 20 result 126314 non-zip object 21 forecast 126314 non-null float64 22 notes 5424 non-null object 23 date_played 126314 non-null datetime64[ns] 24 difference 126314 non-null int64 dtypes: datetime64[ns](1), float64(6), int64(viii), object(10) memory usage: 24.1+ MB Note that in that location'south a new object, renamed_df. Like several other data manipulation methods, .rename() returns a new DataFrame past default. If you desire to manipulate the original DataFrame straight, and then .rename() also provides an inplace parameter that you can gear up to True.
Your dataset might contain columns that you don't demand. For example, Elo ratings may be a fascinating concept to some, merely you won't analyze them in this tutorial. Y'all tin delete the four columns related to Elo:
>>>
>>> df . shape (126314, 25) >>> elo_columns = [ "elo_i" , "elo_n" , "opp_elo_i" , "opp_elo_n" ] >>> df . drop ( elo_columns , inplace = True , axis = 1 ) >>> df . shape (126314, 21) Remember, y'all added the new cavalcade "difference" in a previous case, bringing the total number of columns to 25. When you remove the four Elo columns, the total number of columns drops to 21.
Specifying Data Types
When you create a new DataFrame, either by calling a constructor or reading a CSV file, Pandas assigns a information type to each cavalcade based on its values. While it does a pretty good job, it's not perfect. If y'all choose the correct data type for your columns upfront, then you can significantly improve your code'due south operation.
Accept another wait at the columns of the nba dataset:
Y'all'll see the same output as before:
Ten of your columns take the information type object. Most of these object columns contain arbitrary text, but there are also some candidates for information type conversion. For example, have a await at the date_game column:
>>>
>>> df [ "date_game" ] = pd . to_datetime ( df [ "date_game" ]) Hither, you use .to_datetime() to specify all game dates as datetime objects.
Other columns comprise text that are a chip more than structured. The game_location column tin can have only three dissimilar values:
>>>
>>> df [ "game_location" ] . nunique () 3 >>> df [ "game_location" ] . value_counts () A 63138 H 63138 N 38 Name: game_location, dtype: int64 Which data type would y'all utilise in a relational database for such a cavalcade? You lot would probably not utilize a varchar type, but rather an enum. Pandas provides the chiselled information type for the aforementioned purpose:
>>>
>>> df [ "game_location" ] = pd . Chiselled ( df [ "game_location" ]) >>> df [ "game_location" ] . dtype CategoricalDtype(categories=['A', 'H', 'N'], ordered=False) categorical data has a few advantages over unstructured text. When you specify the categorical data type, y'all make validation easier and relieve a ton of retention, as Pandas will only apply the unique values internally. The higher the ratio of total values to unique values, the more space savings you'll get.
Run df.info() again. You should run into that changing the game_location data type from object to chiselled has decreased the memory usage.
You'll frequently come across datasets with too many text columns. An essential skill for data scientists to accept is the ability to spot which columns they tin catechumen to a more performant data type.
Accept a moment to practise this now. Find another column in the nba dataset that has a generic data type and convert information technology to a more specific one. You tin can aggrandize the code block below to see one potential solution:
game_result can take just 2 different values:
>>>
>>> df [ "game_result" ] . nunique () 2 >>> df [ "game_result" ] . value_counts () 50 63157 W 63157 To improve operation, y'all can convert information technology into a categorical column:
>>>
>>> df [ "game_result" ] = pd . Categorical ( df [ "game_result" ]) You tin use df.info() to check the memory usage.
As you work with more than massive datasets, memory savings becomes especially crucial. Be sure to keep performance in mind as you proceed to explore your datasets.
Cleaning Information
You may exist surprised to observe this section and so late in the tutorial! Unremarkably, y'all'd take a disquisitional look at your dataset to prepare any issues earlier you motility on to a more than sophisticated analysis. Yet, in this tutorial, you'll rely on the techniques that y'all've learned in the previous sections to clean your dataset.
Missing Values
Have yous always wondered why .info() shows how many not-cypher values a column contains? The reason why is that this is vital data. Null values often indicate a trouble in the data-gathering process. They can make several analysis techniques, similar different types of machine learning, difficult or even impossible.
When you audit the nba dataset with nba.info(), yous'll encounter that it'southward quite neat. Just the column notes contains nada values for the majority of its rows:
This output shows that the notes cavalcade has only 5424 not-null values. That means that over 120,000 rows of your dataset take zilch values in this column.
Sometimes, the easiest way to deal with records containing missing values is to ignore them. You can remove all the rows with missing values using .dropna():
>>>
>>> rows_without_missing_data = nba . dropna () >>> rows_without_missing_data . shape (5424, 24) Of grade, this kind of data cleanup doesn't brand sense for your nba dataset, because it's not a problem for a game to lack notes. But if your dataset contains a million valid records and a hundred where relevant data is missing, then dropping the incomplete records can be a reasonable solution.
You can too driblet problematic columns if they're not relevant for your assay. To exercise this, apply .dropna() again and provide the axis=1 parameter:
>>>
>>> data_without_missing_columns = nba . dropna ( axis = one ) >>> data_without_missing_columns . shape (126314, 23) Now, the resulting DataFrame contains all 126,314 games, merely not the sometimes empty notes column.
If there's a meaningful default value for your use case, and so you tin likewise replace the missing values with that:
>>>
>>> data_with_default_notes = nba . copy () >>> data_with_default_notes [ "notes" ] . fillna ( ... value = "no notes at all" , ... inplace = True ... ) >>> data_with_default_notes [ "notes" ] . describe () count 126314 unique 232 top no notes at all freq 120890 Name: notes, dtype: object Here, y'all fill the empty notes rows with the string "no notes at all".
Invalid Values
Invalid values can be even more dangerous than missing values. Often, you tin perform your data analysis every bit expected, but the results you get are peculiar. This is especially important if your dataset is enormous or used manual entry. Invalid values are oftentimes more challenging to detect, only yous can implement some sanity checks with queries and aggregations.
One thing you can do is validate the ranges of your data. For this, .describe() is quite handy. Remember that it returns the following output:
The year_id varies between 1947 and 2015. That sounds plausible.
What nigh pts? How can the minimum exist 0? Let's accept a look at those games:
>>>
>>> nba [ nba [ "pts" ] == 0 ] This query returns a unmarried row:

It seems the game was forfeited. Depending on your analysis, you may want to remove it from the dataset.
Inconsistent Values
Sometimes a value would be entirely realistic in and of itself, but it doesn't fit with the values in the other columns. You can define some query criteria that are mutually sectional and verify that these don't occur together.
In the NBA dataset, the values of the fields pts, opp_pts and game_result should be consequent with each other. You tin can cheque this using the .empty attribute:
>>>
>>> nba [( nba [ "pts" ] > nba [ "opp_pts" ]) & ( nba [ "game_result" ] != 'W' )] . empty Truthful >>> nba [( nba [ "pts" ] < nba [ "opp_pts" ]) & ( nba [ "game_result" ] != 'L' )] . empty True Fortunately, both of these queries return an empty DataFrame.
Be prepared for surprises whenever you're working with raw datasets, especially if they were gathered from dissimilar sources or through a complex pipeline. You might see rows where a team scored more points than their opponent, only all the same didn't win—at least, co-ordinate to your dataset! To avoid situations like this, make certain you add further data cleaning techniques to your Pandas and Python arsenal.
Combining Multiple Datasets
In the previous section, you've learned how to make clean a messy dataset. Another aspect of real-world data is that it often comes in multiple pieces. In this section, you'll learn how to grab those pieces and combine them into one dataset that's ready for analysis.
Earlier, you combined 2 Series objects into a DataFrame based on their indices. Now, you'll accept this one step further and use .concat() to combine city_data with some other DataFrame. Say you've managed to gather some data on two more cities:
>>>
>>> further_city_data = pd . DataFrame ( ... { "acquirement" : [ 7000 , 3400 ], "employee_count" :[ ii , 2 ]}, ... alphabetize = [ "New York" , "Barcelona" ] ... ) This second DataFrame contains info on the cities "New York" and "Barcelona".
Y'all tin can add these cities to city_data using .concat():
>>>
>>> all_city_data = pd . concat ([ city_data , further_city_data ], sort = False ) >>> all_city_data Amsterdam 4200 5.0 Tokyo 6500 8.0 Toronto 8000 NaN New York 7000 2.0 Barcelona 3400 ii.0 Now, the new variable all_city_data contains the values from both DataFrame objects.
By default, concat() combines forth centrality=0. In other words, information technology appends rows. You can also utilize it to suspend columns by supplying the parameter axis=1:
>>>
>>> city_countries = pd . DataFrame ({ ... "country" : [ "Kingdom of the netherlands" , "Japan" , "Kingdom of the netherlands" , "Canada" , "Spain" ], ... "capital" : [ 1 , 1 , 0 , 0 , 0 ]}, ... index = [ "Amsterdam" , "Tokyo" , "Rotterdam" , "Toronto" , "Barcelona" ] ... ) >>> cities = pd . concat ([ all_city_data , city_countries ], centrality = ane , sort = Fake ) >>> cities revenue employee_count country upper-case letter Amsterdam 4200.0 5.0 Kingdom of the netherlands 1.0 Tokyo 6500.0 8.0 Japan 1.0 Toronto 8000.0 NaN Canada 0.0 New York 7000.0 2.0 NaN NaN Barcelona 3400.0 ii.0 Kingdom of spain 0.0 Rotterdam NaN NaN The netherlands 0.0 Note how Pandas added NaN for the missing values. If you lot want to combine only the cities that appear in both DataFrame objects, then you lot tin set the bring together parameter to inner:
>>>
>>> pd . concat ([ all_city_data , city_countries ], axis = ane , bring together = "inner" ) revenue employee_count state capital Amsterdam 4200 5.0 Holland 1 Tokyo 6500 8.0 Japan 1 Toronto 8000 NaN Canada 0 Barcelona 3400 2.0 Espana 0 While it's about straightforward to combine data based on the index, it's non the only possibility. You can utilise .merge() to implement a join performance similar to the one from SQL:
>>>
>>> countries = pd . DataFrame ({ ... "population_millions" : [ 17 , 127 , 37 ], ... "continent" : [ "Europe" , "Asia" , "North America" ] ... }, index = [ "Holland" , "Nippon" , "Canada" ]) >>> pd . merge ( cities , countries , left_on = "country" , right_index = Truthful ) Here, you pass the parameter left_on="country" to .merge() to bespeak what cavalcade you want to bring together on. The upshot is a bigger DataFrame that contains non simply city data, just as well the population and continent of the respective countries:
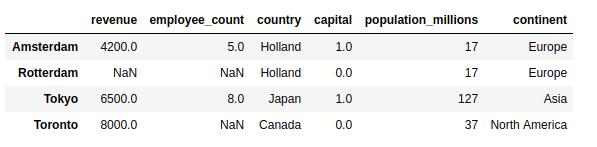
Note that the upshot contains only the cities where the country is known and appears in the joined DataFrame.
.merge() performs an inner join by default. If you lot want to include all cities in the outcome, then you need to provide the how parameter:
>>>
>>> pd . merge ( ... cities , ... countries , ... left_on = "country" , ... right_index = True , ... how = "left" ... ) With this left bring together, you'll see all the cities, including those without country information:
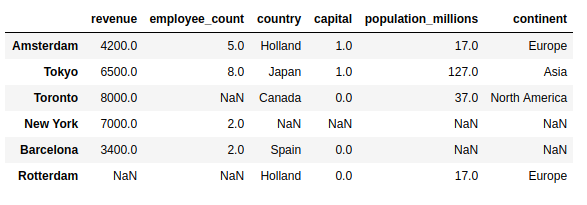
Welcome back, New York & Barcelona!
Visualizing Your Pandas DataFrame
Data visualization is i of the things that works much better in a Jupyter notebook than in a terminal, so go ahead and fire 1 up. If you need help getting started, then check out Jupyter Notebook: An Introduction. You can likewise access the Jupyter notebook that contains the examples from this tutorial past clicking the link beneath:
Include this line to show plots directly in the notebook:
>>>
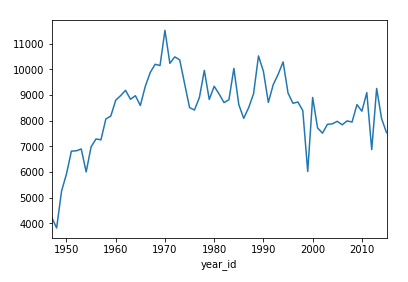
>>> % matplotlib inline Both Series and DataFrame objects have a .plot() method, which is a wrapper around matplotlib.pyplot.plot(). By default, it creates a line plot. Visualize how many points the Knicks scored throughout the seasons:
>>>
>>> nba [ nba [ "fran_id" ] == "Knicks" ] . groupby ( "year_id" )[ "pts" ] . sum () . plot () This shows a line plot with several peaks and two notable valleys around the years 2000 and 2010:
You can also create other types of plots, similar a bar plot:
>>>
>>> nba [ "fran_id" ] . value_counts () . caput ( ten ) . plot ( kind = "bar" ) This will show the franchises with the most games played:
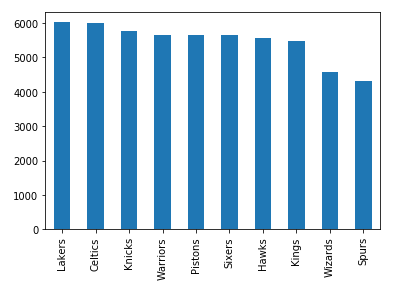
The Lakers are leading the Celtics by a minimal border, and there are six farther teams with a game count higher up 5000.
Now try a more complicated practise. In 2013, the Miami Oestrus won the championship. Create a pie plot showing the count of their wins and losses during that flavor. And so, aggrandize the code cake to come across a solution:
Offset, you ascertain a criteria to include simply the Heat'south games from 2013. Then, you create a plot in the aforementioned way as you lot've seen above:
>>>
>>> nba [ ... ( nba [ "fran_id" ] == "Heat" ) & ... ( nba [ "year_id" ] == 2013 ) ... ][ "game_result" ] . value_counts () . plot ( kind = "pie" ) Here's what a champion pie looks similar:
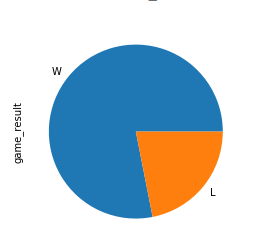
The piece of wins is significantly larger than the piece of losses!
Sometimes, the numbers speak for themselves, but often a nautical chart helps a lot with communicating your insights. To learn more about visualizing your data, check out Interactive Data Visualization in Python With Bokeh.
Conclusion
In this tutorial, y'all've learned how to beginning exploring a dataset with the Pandas Python library. You saw how you could access specific rows and columns to tame even the largest of datasets. Speaking of taming, you lot've likewise seen multiple techniques to fix and clean your data, by specifying the data type of columns, dealing with missing values, and more. You've even created queries, aggregations, and plots based on those.
Now you tin:
- Work with
SeriesandDataFrameobjects - Subset your data with
.loc,.iloc, and the indexing operator - Respond questions with queries, grouping, and aggregation
- Handle missing, invalid, and inconsistent data
- Visualize your dataset in a Jupyter notebook
This journeying using the NBA stats simply scratches the surface of what you can do with the Pandas Python library. Yous tin ability up your project with Pandas tricks, acquire techniques to speed upward Pandas in Python, and even swoop deep to encounter how Pandas works behind the scenes. There are many more features for you to discover, then get out there and tackle those datasets!
You lot can get all the lawmaking examples you lot saw in this tutorial by clicking the link beneath:
Watch Now This tutorial has a related video course created by the Existent Python team. Sentinel information technology together with the written tutorial to deepen your understanding: Explore Your Dataset With Pandas

How To Make A Data Set For Python,
Source: https://realpython.com/pandas-python-explore-dataset/
Posted by: fuentesappotherged.blogspot.com
0 Response to "How To Make A Data Set For Python"
Post a Comment