

Which Of The Following Sets Of Data Has No Variability?
| Variability | |
|---|---|
| Practice Do one: | You lot need to understand the measures of variability to: No Response |
Lesson i: Summary Measures of Information 1.4 - two 
Biostatistics for the Clinician
Let'due south look at the concept of variability. It is basically a fairly simple concept. When you're talking almost variability, you're talking about how scattered or dispersed or spread out the data is. The concept basically has to do with the width of a distribution. In general, other things existence equal, the wider the distribution, the more the variability (come across Figure 2.v below). | Effigy ii.v: Normal Distribution |
|---|
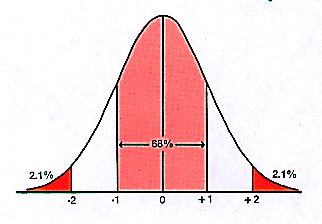 |
So, what variability refers to is how dispersed or spread out the information values are, or looking at it from another indicate of view how wide the information distribution is when it is graphed. If all data values are the same, then, of course, there is zero variability. The graph of the distribution would have zippo width. If all the values prevarication very close to each other at that place is little variability and the distribution's graph would be quite narrow. If, on the other hand, the numbers are spread out all over the identify, there is more than variability and the graph would be wider.
| Variability | |
|---|---|
| Practice Exercise 2: | Variability has to do with the: No Response |
Lesson 1: Summary Measures of Data 1.4 - three
Biostatistics for the Clinician
Again, information technology turns out as was the case with measures of central tendency, that there are many measures of variability. In the medical research literature some of the most frequently used measures are the standard deviation, interquartile range, and the range (encounter Effigy 2.v). | Variability | |
|---|---|
| Exercise Exercise 3: | Variability is measured by: No Response |
Lesson 1: Summary Measures of Data 1.4 - 4
Biostatistics for the Clinician
1.4.two Standard Deviation
One way to measure the spread of information or data is past looking at the standard divergence. Information technology's only the mean spread which you extract from the data (run across the standard deviation formula beneath).| Standard Divergence Formula |
|---|
 |
To get the standard deviation, equally you tin can come across in the formula, first you foursquare the distances values are from the mean. Then you sum those squared differences. Then you lot divide that sum by the number of differences. Finally, you have the square root of that caliber. The reaon that you subtract and square is pretty clear. Whether the value is above the hateful or below the mean the squared divergence betwixt the value and the hateful comes out the same when it is squared. So positive and negative makes no difference here. If you didn't square, they would tend to cancel each other out. When you dissever past the number of values to become an boilerplate you find the square root of the whole thing because, it was squared before, to get back to the original measures. In other words by squaring to get rid of the negative and positive values you get squared measures. So you accept the square root to go back to the original more than intuitive kinds of measures like feet, cubic inches, or whatever else it might be. The standard deviation can be idea of as the average distance that values are from the mean of the distribution (encounter the standard divergence formula higher up).
| Variability | |
|---|---|
| Practice Exercise 4: | The standard deviation measures: No Response |
Of course, given the formula, to compute a standard deviation you lot must be able to compute a meaningful mean. Consequently, computation of the standard deviation requires interval or ratio variables. Furthermore, in a distribution having a bong (normal) curve, it always turns out that when you know the standard departure, yous also know that approximately 68% of the values lie within 1 standard deviation of the mean. You besides know that approximately 2.1% of the values lie in each tail of the distribution beyond 2 standard deviations from the mean (again see Figure 2.v).
| Variability | |
|---|---|
| Practice Do 5: | In a normal distribution the per centum of scores within 1 standard deviation of the mean is approximately: No Response |
Lesson 1: Summary Measures of Data 1.4 - v
Biostatistics for the Clinician
one.4.3 Interquartile Range
You should recall that the median is the betoken in the distribution that 50% of the sample is below and fifty% is above. In other words the median is at the 50th percentile. Quartiles can also be divers. The 1st quartile is at the 25th percentile. The 2nd quartile is at the 50th percentile. The 3rd quartile is at the 75th percentile. And, the fourth quartile is at the 100th percentile.The interquartile range then extends from the 25th percentile to the 75th percentile. It includes 50% of the values in the sample. So, the interquartile range is the distance between the 25th percentile and the 75th percentile. The interquartile range and then is another measure of variability. But unlike the standard deviation, information technology tin can exist appropriately applied with ordinal variables. Therefore information technology is used specially in conjunction with nonparametric statistics (see the interquartile range in the effigy beneath).
| Ranges |
|---|
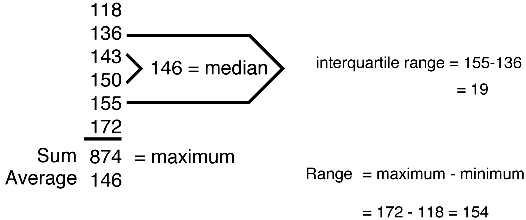 |
And so, another way to display data that's been proposed by exploratory data analysis is to rank the information from low to loftier, and so find the median then the quartile values, the values between which one one-half of the data resides. When you practice this you can and so plot a box plot containing half the information (see the figure beneath). The balance of the data is out in the wings. And, you lot can run across the interquartile range which contains those values betwixt the lower and upper quartiles. Yous'll encounter more explicit clinical medicine examples of this in Lesson 1.five.
| Exploratory Information Analysis |
|---|
 |
| Variability | |
|---|---|
| Do Practice half-dozen: | Is it appropriate to compute the standard deviation when the data consists of rankings? No Response |
Lesson 1: Summary Measures of Information 1.4 - 6
Biostatistics for the Clinician
1.4.4 Range
The range is just the difference between the highest and lowest value in the sample (meet the figure below). It's a unproblematic measure to compute and to understand. Unfortunately, it is particulary sensitive to extreme scores on the one manus and lacks sensitive to varying values between those extremes. All the same you come beyond it adequately frequently in the literature.| Ranges |
|---|
| |
| Variability | |
|---|---|
| Practice Practise 7: | The range measures: No Response |
Lesson one: Summary Measures of Data 1.4 - 7

Which Of The Following Sets Of Data Has No Variability?,
Source: https://www.uth.tmc.edu/uth_orgs/educ_dev/oser/L1_4.HTM
Posted by: fuentesappotherged.blogspot.com
0 Response to "Which Of The Following Sets Of Data Has No Variability?"
Post a Comment